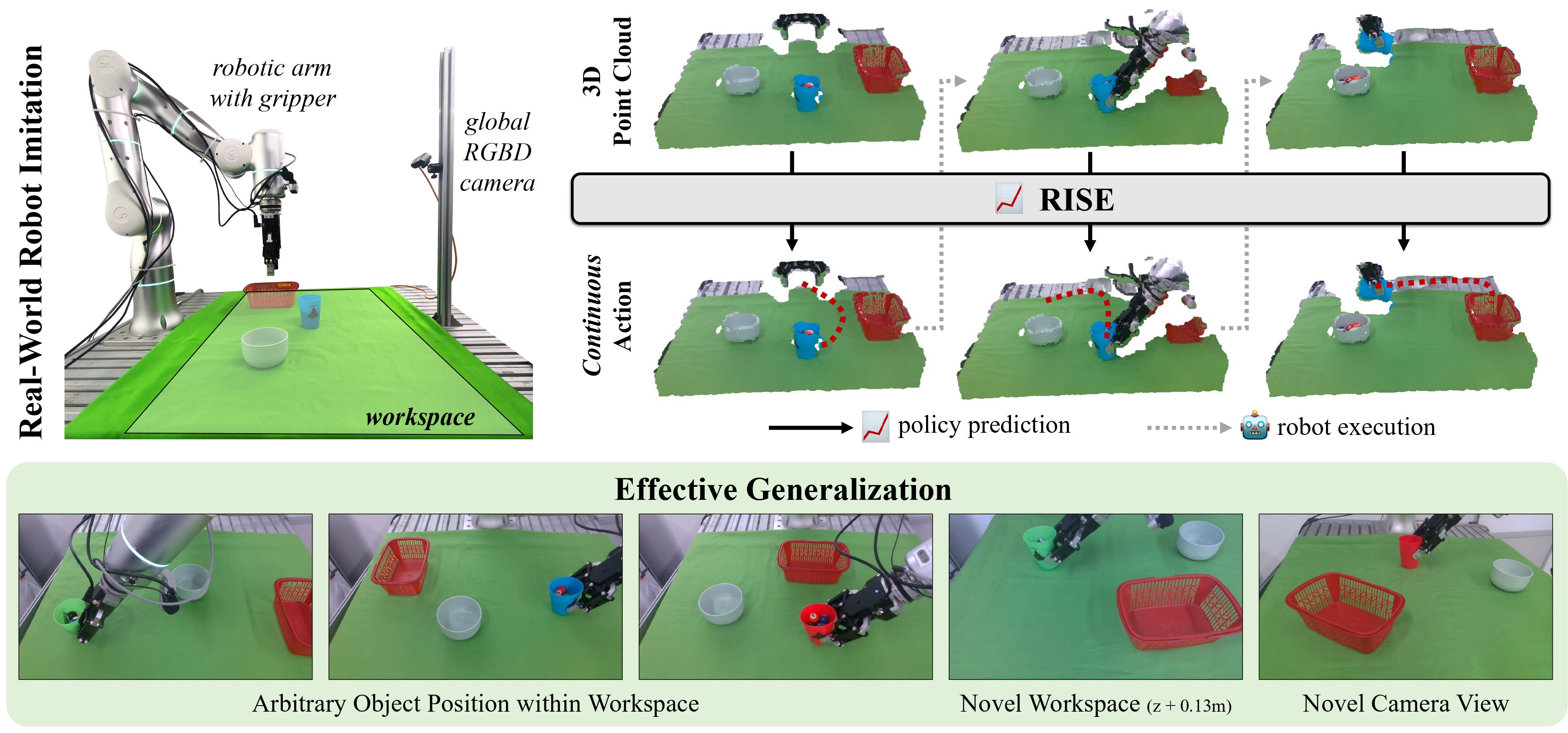
Precise robot manipulations require rich spatial information in imitation learning. Image-based policies model object positions from fixed cameras, which are sensitive to camera view changes. Policies utilizing 3D point clouds usually predict keyframes rather than continuous actions, posing difficulty in frequently changing scenarios. To utilize 3D perception efficiently, we present RISE, an end-to-end baseline for real-world imitation learning, which predicts continuous actions directly from single-view point clouds. It compresses the point cloud to tokens with a sparse 3D encoder. After adding sparse positional encoding, the tokens are then featurized using a transformer. Finally, the features are decoded into robot actions by a diffusion head. Trained with 50 demonstrations for each real-world task, RISE surpasses currently representative 2D and 3D policies by a large margin, showcasing significant advantages in both accuracy and efficiency. Experiments also demonstrate that RISE is more general and robust to environmental change compared with previous baselines.
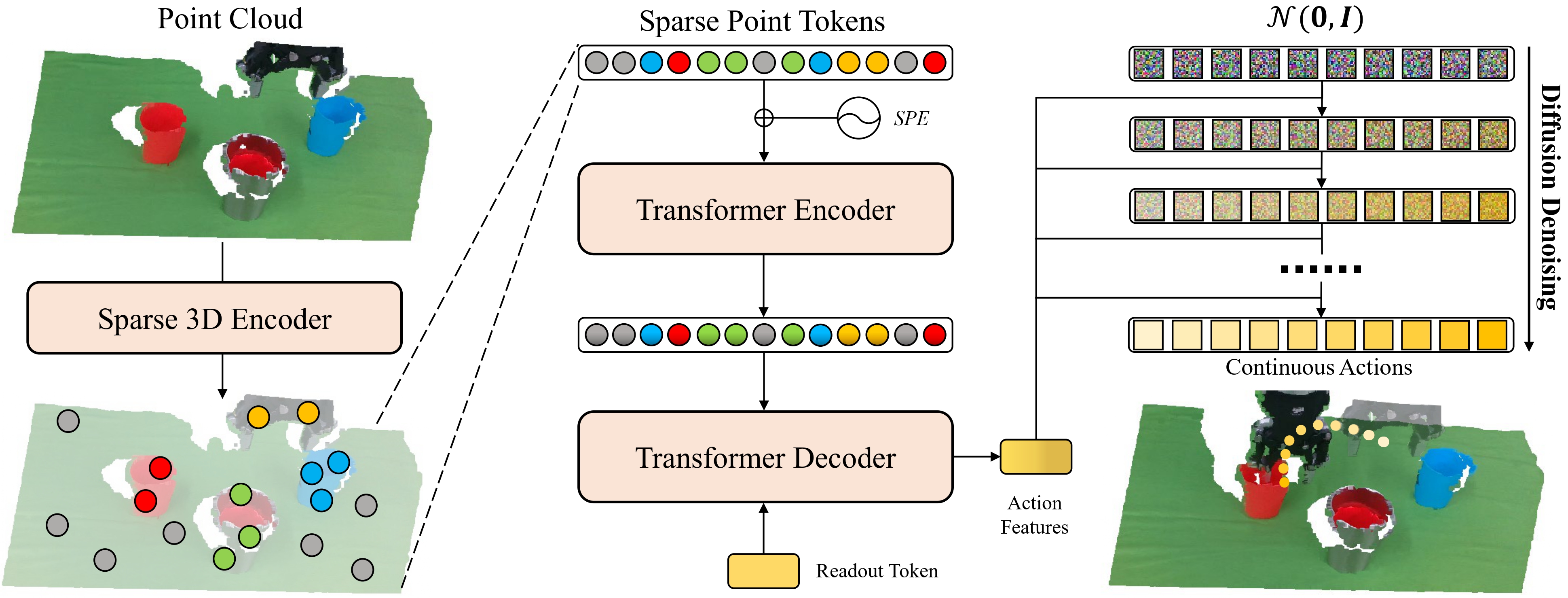
The input of RISE is a noisy point cloud captured from the real world. A 3D encoder built with sparse convolution is employed to compress the point cloud into point tokens. The tokens are fed into the transformer encoder after adding sparse positional encoding. A readout token is used to query the action features from the transformer decoder. Conditioned on the action features, the Gaussian samples are denoised into continuous actions iteratively using a diffusion head.
We carefully designed 6 tasks from 4 types for the experiments: the pick-and-place tasks (Collect Cups and Collect Pens), the 6-DoF tasks (Pour Balls), the push-to-goal tasks (Push Block and Push Ball) and the long-horizon tasks (Stack Blocks). We evaluate RISE and various baselines (2D: ACT and Diffusion Policy; 3D: Act3D and DP3) on these tasks. In the following sections, all the videos are autonomous rollouts of the RISE policy.
Collect Cups. Collect the cups into the large metal cup.
Collect Pens. Collect the marker pens into the bowl.
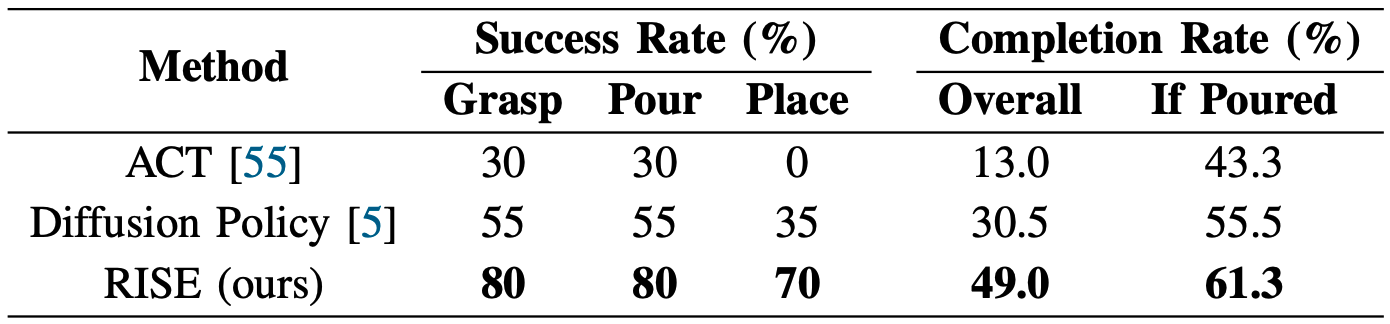
Pour Balls. Grasp the cup, pour the balls in the cup to the bowl, and drop the cup into the basket.
Push Block. Push the block into the goal area using the gripper.
Push Ball. Push the soccer ball into the goal area using the marker pen.

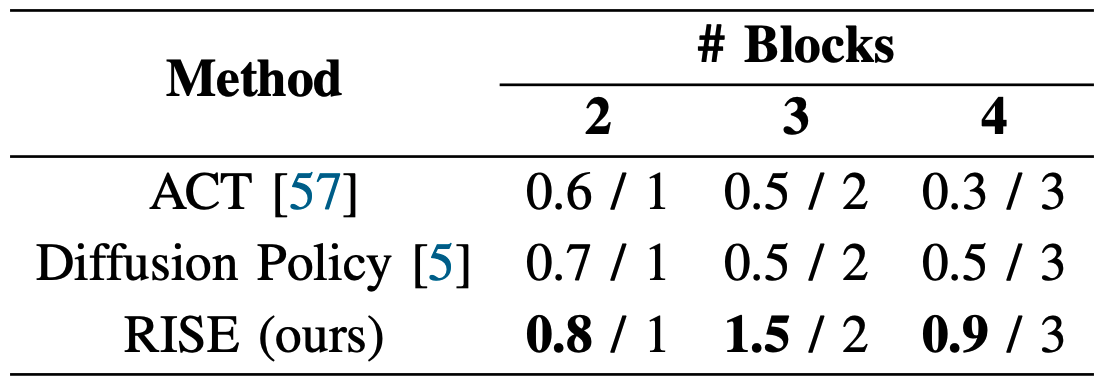
Stack Blocks. Stack the blocks together in the order of block size.
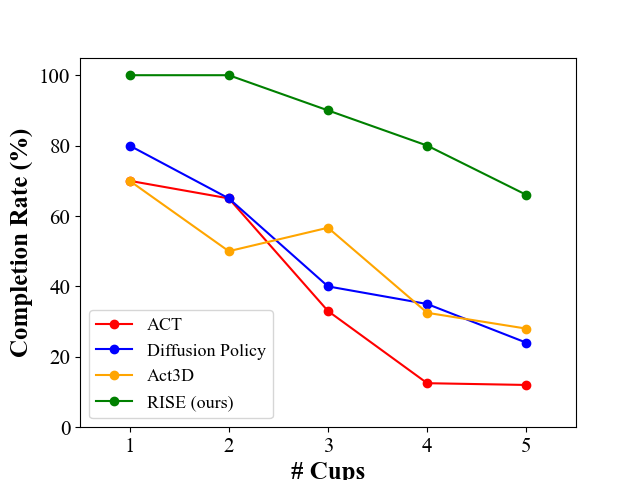
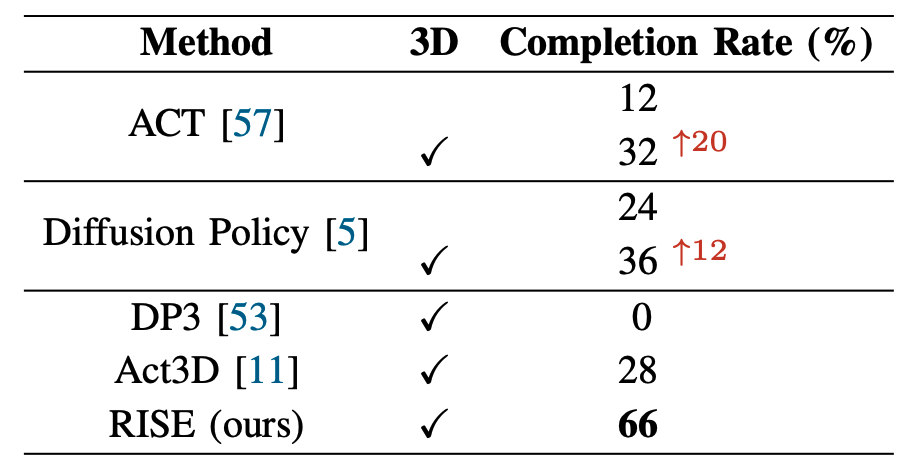
We explore how 3D perception enhances the performance of robot manipulation policies on the Collect Cups task with 5 cups. We replace the vision encoders in image-based policies Diffusion Policy and ACT with our 3D perception module. We observe a significant improvement in the performance of ACT and Diffusion Policy after applying 3D perception, even surpassing the 3D policy Act3D and recently proposed DP3, which reflects the effectiveness of our 3D perception module in manipulation policies.
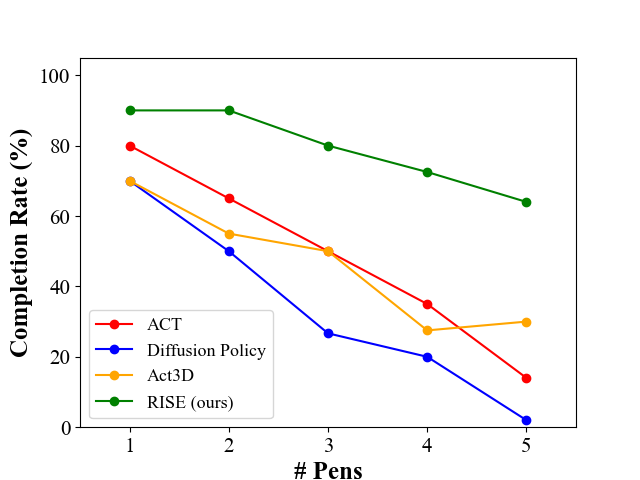
We evaluate the generalization ability of different methods on the Collect Pens task with 1 pen under different levels of environmental disturbances as follows.

@article{wang2024rise,
title = {RISE: 3D Perception Makes Real-World Robot Imitation Simple and Effective},
author = {Chenxi Wang and Hongjie Fang and Hao-Shu Fang and Cewu Lu},
journal = {arXiv preprint arXiv:2404.12281},
year = {2024}
}